Mehr
Auswählen
Gestaltung der Zukunft
künstlicher Intelligenz
Entwicklung von KI-Systemen
der nächsten Generation
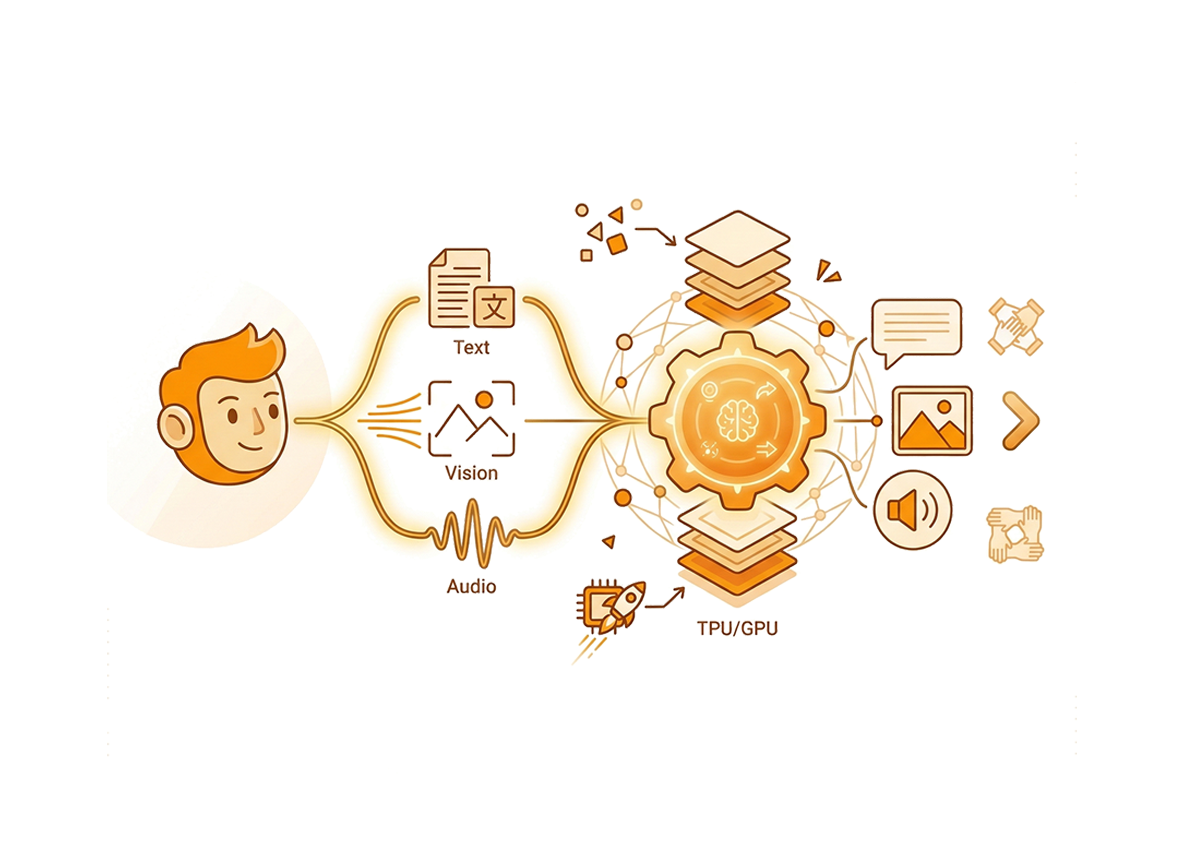
Omni-Modale Intelligenz
Vereint über alle Modalitäten
Duplex-Verarbeitung
Echtzeit-Multi-Stream-Ein- und Ausgabe
Lernen Sie CausalLM kennen
Eine gemeinnützige Forschungsinitiative zur Förderung omni-modaler KI.
Wir entwickeln Basismodelle, die alle Modalitäten verstehen und generieren können.
Unabhängige Forschung zu effizienten Architekturen, Streaming und synthetischen Daten.