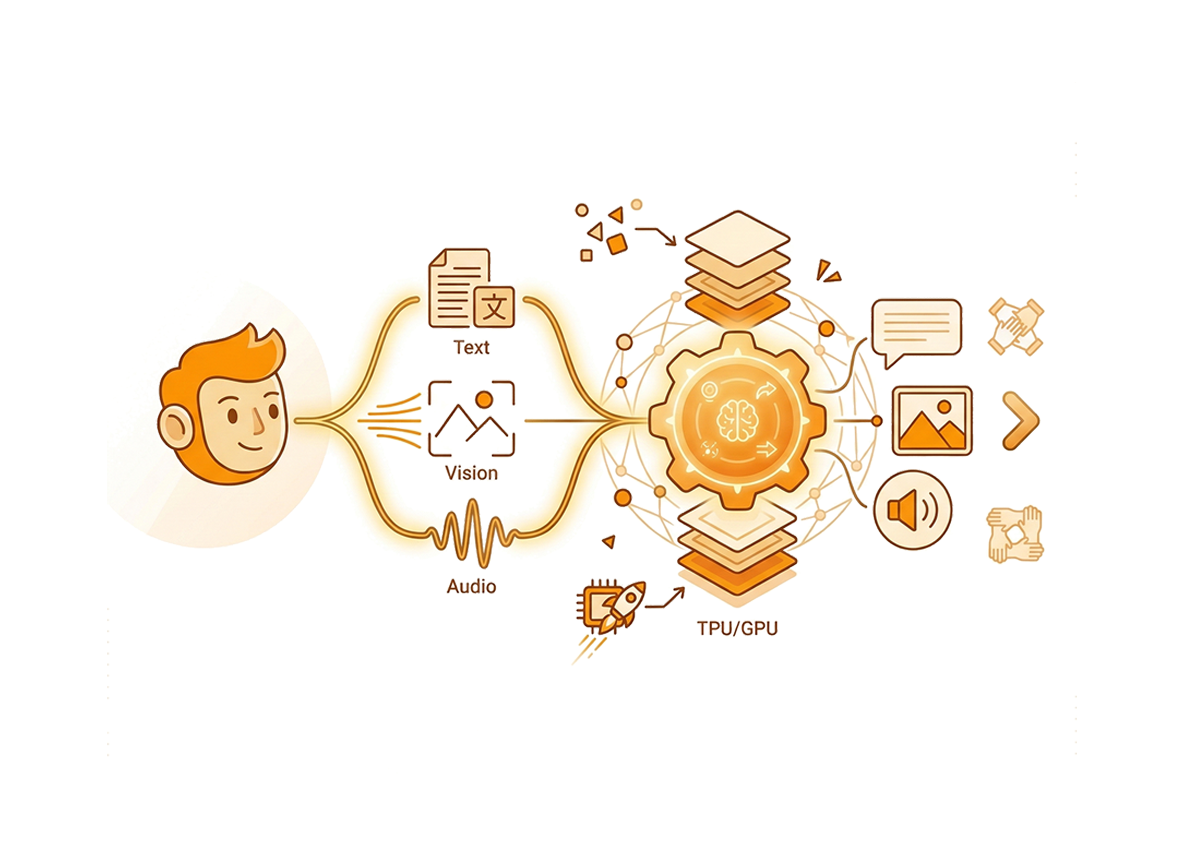
一个致力于推动人工智能前沿发展的非营利研究组织。我们专注于全模态AI系统、高效架构和大规模合成数据。
一个推动全模态人工智能发展的非营利研究组织。
开发能够以近零延迟理解和生成文本、图像、音频和视频的大型语言模型。
构建同时处理多个并发音频、视频和数据输入流的系统,无需轮流限制。
创建基于跨语言、文档和长上下文场景的事实知识的大规模合成数据集。
将高效注意力机制扩展到100万以上Token,用于全天任务记忆和上下文学习。
我们很高兴地宣布,我们的CausalLM Omni模型的一个中间预览评估点现在向我们的战略合作伙伴开放。
Retrievatar 是一个多模态数据集,旨在增强视觉语言模型的检索增强生成能力,特别关注虚构的动漫角色和现实世界的各界名人。